Hannah Fry is one of those annoyingly accomplished people that make you realise how little you've achieved in life; for more details, see her Wikipedia page. She's now a Cambridge academic, and I don't think we've ever met, though another thing that her page told me is that she grew up in my childhood home town of Ware, and attended the same school as many of my friends... but nearly 20 years later, which makes her scale of accomplishments since school even more annoying!
She's a great natural communicator – something not traditionally associated with Maths professors, but their numbers seem to be increasing! – and has made various short YouTube videos in the past.
But this month she released a longer one, which I'd highly recommend if you're interested in AI Agents but are (rightly) nervous about trying it yourself: watch Hannah do so instead! A great introduction to why they are both seductive and very scary.
I created my first neural network back in the late 90s, as part of my Ph.D, to do handwriting recognition on images of whiteboards. It wasn't a very good network; I had to write the whole thing from scratch as there weren't any suitable off-the-shelf libraries available, I didn't know much about them, and I didn't have nearly enough training data. I quickly abandoned it for a more hand-tailored system. But one of the early textbooks I was reading at the time had a quote, I think from John S Denker, which I've never forgotten: "Neural networks are the second-best way to do almost anything."
In other words, if you know how to do it properly, for example by evaluating rules, or by rigorous statistical analysis, don't try using a neural network. It will introduce inaccuracies, unpredictability, and make it very much harder either to prove that your system works, or to debug it when anything goes wrong.
The problem is that there are many situations in which we don't know how to do it 'properly', or where writing the necessary rules would take far too much time. And 'machine learning', the more generic term encompassing neural networks and similar trainable systems, has advanced amazingly since I was playing with it. For many tasks, we also now have masses of data available, thanks to the internet. (I was playing with my toy system at about the same time as I was experimenting with these brand new 'web browsers'.) So while it remains the case, as a Professor of Computer Science friend of mine likes to put it, that "Machine learning is statistics done badly", it can still be exceedingly useful. It would almost certainly be the right way for me to do my handwriting-recognition system now, for example, and over the last few decades we've discovered lots of other pattern-matching operations for which it is essential - analysing X-rays for evidence of tumours is just one example where it has saved countless lives.
But all of this is nothing new. So why the current excitement about 'AI'? After all, 'artificial intelligence', like 'expert system', is one of those phrases we heard a lot in the 70s and 80s but had largely abandoned in more recent decades, until it came back with a rush and is now the darling of every marketing department. Every project that involves any kind of machine learning (and many things that don't) will now be reported with 'AI' somewhere in the title of the article, even though it has nothing to do with ChatGPT, Claude, or Gemini.
And the reason is that, by appearing to have an understanding of natural language, generative LLMs have opened up the power of many of these systems to the non-technical general public, in the same way that the web browser in the 90s opened up the power of the Internet, which had also been in existence for decades beforehand, to ordinary users. (Many people ended up thinking the Web was the Internet, just as many people probably think ChatGPT has something to do with newspaper headlines about AIs diagnosing cancer.)
But it's not an analogy I'd like to push too far, because the technology of the World Wide Web did not invent new data, did not mislead people, did not presume to counsel them or tell them that it loved them. The similarity is that you needed to be something of an expert to make use of the Internet before the web, and you were therefore probably better able to judge what you might learn from it. If machine learning is statistics done badly, then 'AI' is machine learning made more unreliable, sounding much more plausible, and sold to the more gullible. Take any charlatan and give him skills in rhetoric, and you make him much more dangerous.
Regular readers will know that I am quite a cynic when it comes to most current uses of AI, and I consider myself fortunate that I was able to spot lots of its failings very early on. A few recent examples from ChatGPT, Gemini and other systems, some of which have been reported here, include:
Telling me that one eighth of 360 degrees was 11.25 degrees. (Don't trust it to do your financial planning!)
Telling a teenage friend that the distance from Cambridge to Oxford was 180 miles; she swallowed that whole and repeated it to me confidently. (It's actually more like 80 miles.)
Telling me that my blog was written by... well, several other people over the years, some of whom were flattering possibilities! (But there are several thousand pages here which all say "Quentin Stafford-Fraser's Blog" at the top.)
Suggesting a Greek ferry to a friend, as a good way to get to Santorini in time for our flight. (It didn't actually run on the days suggested, and we would have missed our flight if we had relied on it.)
And of course, the press has regular reports of more serious problems:
So, some time ago, I announced Quentin's AI Maxim, which states that
"You should never ask an AI anything to which you don't already know the answer".
And for those who say, "But the AI systems have got a lot better recently!", I would agree. Some of my examples are from a few months ago, and a few months is a long time in AI. But I would also point out that, on Friday, when I asked the latest version of Claude to suggest some interesting places for a long weekend in our campervan, within about 2 hours' drive from Cambridge, one of its suggestions was Durham, which would probably take you twice that if you didn't stop on the way. I pointed this out, and it agreed.
"You're right to question that...I shouldn't have included it. Apologies for the error..."
Now, if I had been asking a human for suggestions, they might have said, "Mmm. What about Durham? How far is that from here?" But the biggest danger with these systems is that they announce facts just as confidently when they are wrong as when they are right, and they will do that whether you are asking about a cake recipe or about treatment for bowel cancer. Fortunately, I already knew the answer when it came to the suitability of Durham for a quick weekend jaunt!
But here's the thing...
Thirty-four years ago, I was very enthusiastic about two new technologies I had recently discovered. One was the Python programming language. The other was the World Wide Web. In both cases, more experienced research colleagues were dismissive. "It's not a proper compiled language." "We've seen several hypertext systems before, and none of them has really caught on." They were probably about the age that I am now. So, I don't want to be 'that guy' when it comes to AI. (Though I'm glad I *was* when it came to blockchains, cryptocurrencies and NFTs!)
All of which brings to mind that wonderful quote from Douglas Adams:
"There's a set of rules that anything that was in the world when you were born is normal and natural. Anything invented between when you were 15 and 35 is new and revolutionary and exciting, and you'll probably get a career in it. Anything invented after you're 35 is against the natural order of things."
So in the last few weeks I have been doing some more extensive experiments with AI systems, mostly using the paid-for version of Claude, and the results have often been very impressive. They can be great brainstorming tools; I have to admit that some of the suggestions as to where we might go in our campervan were good ones... I'm just glad I didn't select the Durham option. They can be great search engines... just don't believe what they tell you without going to the source, or you too may have to call the coastguard.
But perhaps I should modify the 2026 version of Quentin's AI Maxim to say something like:
You should never ask an AI anything where you don't have the ability, and the discipline, to check the answer.
And one of the areas where checking the answer can sometimes be an easier and more rigorous process is in the writing of software. I've been doing that a fair bit recently, and will write about that shortly.
In the meantime, I leave you with this delightful YouTube short from Steve Mould. His long-form videos are always interesting - he has 3.5M followers for a good reason - and though I tend to avoid 'shorts' in general, this is worth a minute and half of your time.
I wrote a post back in July called 'The AI Heat Pump', about how AI systems can expand small amounts of text into larger amounts and condense larger amounts back into small amounts again, simply burning energy and introducing the odd inaccuracy as they go.
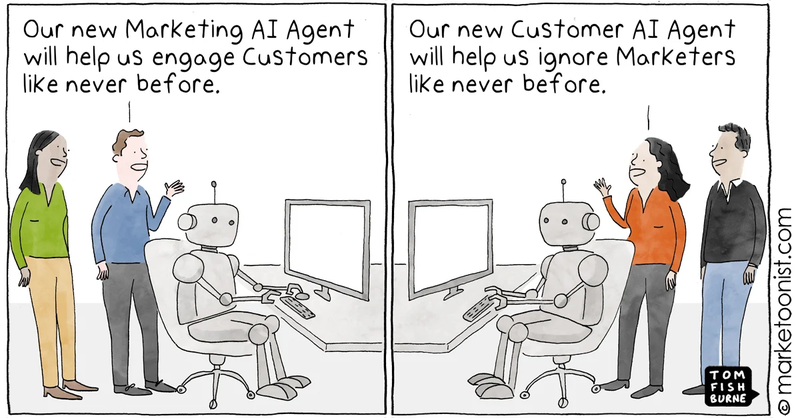
So my thanks to John Naughton for introducing me to Tom Fishburne's site 'Marketoonist' via this cartoon:
A couple of years later, everyone's talking about 'agentic systems', and he has a nice update on this theme:
It's a great site, especially if you've been involved in technology, or marketing, or both. Take a look at more of the cartoons here.
And they're not just pictures, BTW, there are posts behind them, if you click through.
My friend Michael is a jolly good photographer, and I remember him telling me long ago, when he first started posting them online, that he'd had a comment from someone saying, "Your camera takes really nice photos!"
To which Michael had replied, "Thanks! Your keyboard writes really nice comments!"
Little did we know, back then, what was in store...
--
I have a sneaking suspicion that one of my clients is using a GPT to write some of his emails. I've had two or three in recent months that are just too carefully formatted: with nicely boldfaced section headings, too many bullet points, no typos, and they're just a bit too verbose: they read more like a legal document, a press release or a bad Powerpoint presentation than like a message to someone you've known for years.
My immediate reaction was that wonderful phrase I heard recently in an AI-related discussion: "Why would I want to read what somebody couldn't be bothered to write?" And if I knew that it was an LLM, and not a human, that had written it, that might have been my response. But I wasn't quite sure.
And this makes me think that accusing someone of using an AI, if in fact they haven't, could become a dreadful insult - I'd certainly take it that way. "You write like a machine." And, actually, one of the reasons I'm fairly confident that this particular chap is using it for some of his messages is that he also sends me missives which are much more human, and sound like him, and the difference is noticeable.
Unfortunately, kids aren't always smart enough to detect this distinction, and schools and colleges are finding they must now emphasise, to a much greater degree than in the past, that the essay a student produces for their assignment -- the end result -- has no value in itself. Your teacher isn't looking forward to receiving it because he really wants to have your great work of literature to keep on his bookshelf. No, it's the process of writing that essay that is the valuable thing, and doing so is the only thing that will help you when you're in the exam room at the end of the year without the help of ChatGPT (or 'CheatGPT' as I've recently heard it called). The recent idea that continuous assessment is a fairer way to assess students than the rather artificial world of exams is therefore being turned on its head.
--
In the early 18th century, Alexander Pope published his poem 'An Essay on Criticism', which introduced us to such phrases as 'A little learning is a dangerous thing', and 'Fools rush in where angels fear to tread'.
Think about that second one, for a moment . Can you imagine ChatGPT and its ilk ever coming up with that beautiful and succinct phrasing which incorporates so much human tradition and experience in just eight words? No, of course not. It might repeat it, if it had found it elsewhere, but it would never originate it.
AI systems are trained on the bulk of the data to be found on the internet, and they statistically predict what words and phrases might come next based on what they've seen most frequently. An AI's output will always be average, and never excellent. If you're lucky, then your AI will have been trained more on quality content than on the random output of the hoi polloi, and it might produce output which is in some senses slightly above average, but it is nevertheless always just plagiarising large numbers of humans.
Another famous line from An Essay on Criticism is the wonderful
To err is human; to forgive, divine.
And it was in the late 1960s -- yes, as early as that! -- that the newspaper columnist Bill Vaughan came up with a pleasing and much-quoted variation:
To err is human, to really foul things up requires a computer.
But I would suggest that we now need to revise that for our current age.
"To err is human, to excel is human, but to be truly average requires a computer."
Back in January I wrote about how Microsoft had increased their Office subscription prices by a third, but you could still get it for the old price by saying that you wanted to cancel, and then selecting the 'Microsoft 365 Family Classic', which comes without all of the AI features that lead to the extra cost.
Well, our subscription just came up for renewal... and I found that they've now removed that option from the website. In fact, there's nothing on the website to suggest that writing a letter without the aid of AI is something you might want to do... or appreciating that you might not want to pay for it.
Undeterred, though, I used the online chat system. It was AI, of course, but, to be fair, I was able to get through to a human pretty quickly. She had some standard auto-generated responses about all the wonderful things AI could do for me, and a set of questions she needed to ask me about why I didn't want AI to improve my productivity in my Office suite. I said, roughly:
(a) It costs money.
(b) I'm concerned about the environmental impact.
(c) Im concerned about the privacy implications.
(d) I've used the the tools, and know that the supposed productivity improvements are mostly a myth unless you're writing stuff that nobody would want to read... in which case, why bother?
(e) We went to school, so we already know how to write.
I could have added that:
(f) I almost never use Microsoft Office, so wouldn't look there for any of this stuff anyway, and
(g) Modern Microsoft apps are quite bloated enough without wanting to add anything more, and
(h) The only things I might want to use AI for I can get for free from chat.bing.com or chatgpt.com or aistudio.google.com or claude.ai, so I'd rather spend my 25 quid on fish and chips and beer at a nice waterside pub, thank you very much.
But even without those additions, in the end she admitted that she could actually renew my Microsoft 365 Family Classic subscription for the old price.
So it's still possible, if you can manage to talk to a human. But I wonder for how much longer...
The Django web framework is now 20 years old. Within a few months of its launch, I discovered it, liked it, and we rather daringly decided to bet on it as the basis for the software of my new startup. (Here's my post from almost exactly 20 years ago, explaining the decision.)
For those not familiar with them, web frameworks like this give you a whole lot of functionality that you need when you want to use your favourite programming language to build web sites and web services. They help you receive HTTP requests, decide what to do based on the URLs, look things up in databases, produce web pages from templates, return the resulting pages in a timely fashion, and a whole lot more besides. You still have to write the code, but you get a lot of lego bricks of the right shape to make it very much easier, and there are a lot of documented conventions about how to go about it so you don't have to learn, the hard way, the lessons that lots of others had to learn in the past!
Anyway, I had made a similar lucky bet in 1991 when the first version of the Python programming language was released, and I loved it, and was using it just a few weeks later (and have been ever since).
Django was a web framework based on Python, and it has gone on to be a huge success partly because it used Python; partly because of the great design and documentation build by its original founders; partly because of the early support it received from their employer, the Kansas newspaper Lawrence Journal-World, who had the foresight to release it as Open Source; and partly because of the non-profit Django Software Foundation which was later created to look after it.
Over the last two decades Django has gone on to power vast numbers of websites around the world, including some big names like Instagram. And I still enjoy using it after all that time, and have often earned my living from doing so, so my thanks go out to all who have contributed to making it the success story that it is!
Anyway, on a podcast this week of a 20th-birthday panel discussion with Django's creators, there was an amusing and poignant story from Adrian Holovaty, which explains the second part of the title of this post.
Adrian now runs a company called Soundslice (which also looks rather cool, BTW). And Soundslice recently had a problem: ChatGPT was asserting that their product had a feature which it didn't in fact have. (No surprises there!) They were getting lots of users signing up and then being disappointed. Adrian says:
"And it was happening, like, dozens of times per day. And so we had this inbound set of users who had a wrong expectation. So we ended up just writing the feature to appease the ChatGPT gods, which I think is the first time, at least to my knowledge, of product decisions being influenced by misinformation from LLMs."
Note this. Remember this day. It was quicker for them to implement the world as reported by ChatGPT than it was to fix the misinformation that ChatGPT was propagating.
In one of my YouTube videos, I talk about how I've wired up my solar/battery system to ensure the energy in my home battery isn't ever used to charge my car (which has a much bigger battery, so doing this doesn't normally make sense), while still allowing the car to be charged using any excess solar power.
I had a query from somebody who was confused about how it worked, so I did my best to answer, and we went to and fro in what became a decent-length conversation. He has a similar inverter to me, but had some fundamental misunderstandings about how it worked.
At first, I assumed this was because he had different goals: he lives in another part of the world where there's a lot more sun and a much less reliable electricity supply, for example. But no, it turned out he wanted to do the same thing as me, but was convinced it wouldn't work the way I had described it.
It turned out, in the end, that the source of his confusion was that he had asked four different LLMs (ChatGPT, Claude, Perplexity, and Grok) about how to configure the system, and they had all agreed that 'battery power is never used to power loads on the "Grid" port', which is actually incorrect.
What persuaded him, in the end, that my description was right, and that all four LLMs were wrong?
People have too inflated sense of what it means to "ask an AI" about something. The AI are language models trained basically by imitation on data from human labelers. Instead of the mysticism of "asking an AI", think of it more as "asking the average data labeler" on the internet.
...
But roughly speaking (and today), you're not asking some magical AI. You're asking a human data labeler. Whose average essence was lossily distilled into statistical token tumblers that are LLMs. This can still be super useful of course. Post triggered by someone suggesting we ask an AI how to run the government etc. TLDR you're not asking an AI, you're asking some mashup spirit of its average data labeler.
If I buy full-fat milk and dilute it 50/50 with water, do I effectively have semi-skimmed milk, or is there something more sophisticated about the skimming process?
And if I then dilute it again, do I get skimmed milk... for one quarter of the price?
Now, the quick answer, as I understand it, is 'no': milk contains a variety of nutrients, and several of these are water-soluble. So the process of 'skimming' to reduce the fat content doesn't dilute these nutrients in the way that you would by just adding water: you still get them at approximately the same concentration when you buy semi-skimmed or skimmed milk.
But I learned a couple of interesting different things from asking!
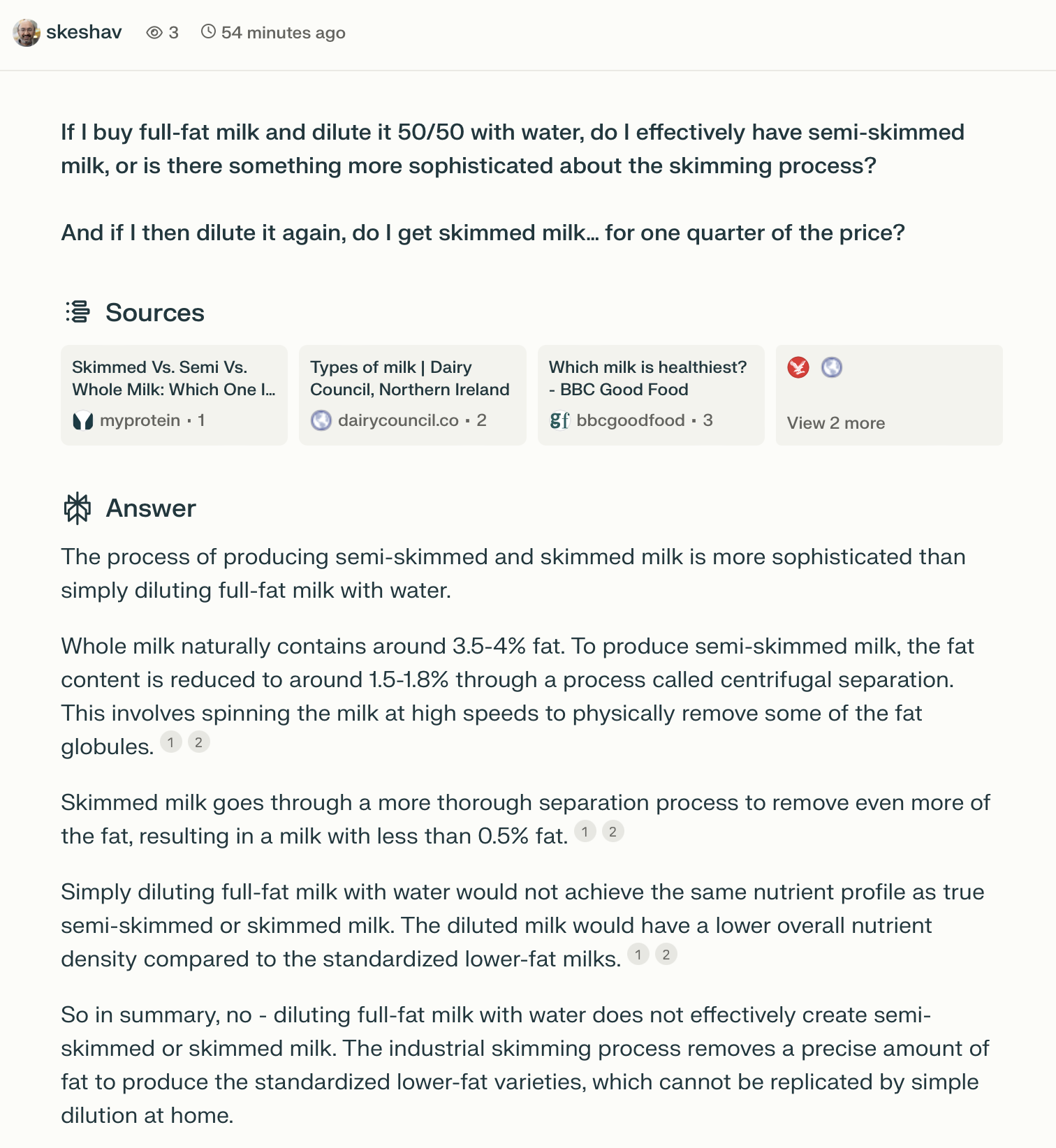
The first thing is this wonderful diagram, found and posted in the comments by Spencer:
(click for full size)
It looks like something explaining the petrochemical industry, but much, much more yummy.
His comment: "I wonder how many of these I can have with my breakfast today?"
And the second thing is that, as well as beginning "Here's a question, O Internet", I could have asked "Here's a question, O Artificial Intelligence".
My friend Keshav did that, submitting my question verbatim to Perplexity, a system I hadn't previously tried. Here's the rather good result (and here as a screenshot in case that live link goes away).
I then went on to ask "Which nutrients in milk are water-soluble?", and it told me, with good citations, with the comment that "maintaining adequate levels of these water-soluble vitamins in breast milk is important for the health and development of the breastfed infant". So I asked a follow-up question: "Is this different in cows' milk?", and again, got a useful, detailed response with references for all the facts.
This stuff really is getting better... at least until the Internet is completely overrun by AI spam and the AIs have to start citing themselves. But for now, I think Perplexity is worth exploring further.
Andrew Curry's thoughtful newletter 'Just Two Things' arrives in my inbox three times a week (which, I confess, is slightly too often for me always to give it the attention it deserves). The two things he talks about today included some gems, though.
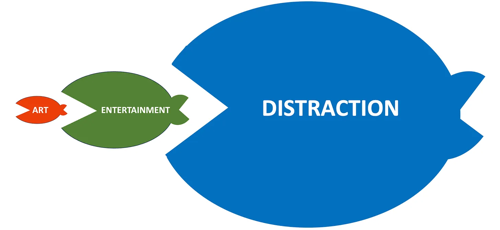
First, he looks at Ted Gioia's article, The State of the Culture, 2024 , which comes with the subtitle 'Or a glimpse into post-entertainment society (it's not pretty)'.
Gioia talks about the old dichotomy between Art and Entertainment:
Many creative people think these are the only options—both for them and their audience. Either they give the audience what it wants (the entertainer's job) or else they put demands on the public (that's where art begins).
but he then describes how a dopamine-driven world is changing that into something more complex and rather more worrying. This is only the beginning:
It's a good and interesting piece, and well worth reading, but if you find it depressing you should also read Curry's comments, which suggest things may not be as bad as they seem.
In the second of his Two Things, Curry talks about an article by Paul Taylor in the London Review of Books. (So, yes, you're reading my comments on Andrew Curry's comments on Paul Taylor's comments on other people's books. This is starting to resemble that fish picture above!)
The Taylor article is also very good, and I won't repeat too much of it here. I will, however, quote a section that Curry also quotes:
We should be genuinely awestruck by what ChatGPT and its competitors are capable of without succumbing to the illusion that this performance means their capacities are similar to ours. Confronted with computers that can produce fluent essays, instead of being astonished at how powerful they are, it's possible that we should be surprised that the generation of language that is meaningful to us turns out to be something that can be accomplished without real comprehension.
I like this, because it echoes Quentin's First Theorem of Artificial Intelligence, which I proposed here about a year ago.
What really worries people about recent developments in AI is not that the machines may become smarter than us.
It's that we may discover we're not really much smarter than the machines.
Again, the LRB article is well worth your time, if you can get through it before being distracted by things which offer you more dopamine.


{kind=link}