When not to Excel
![]() Back in about 1993, I was doing the bookkeeping for a big project being undertaken by my local church. Donations were flooding in, and we needed to keep track of everything, send out receipts, forms and letters of thanks, and note whether each donation was eligible for the UK tax relief known as 'Gift Aid'.
Back in about 1993, I was doing the bookkeeping for a big project being undertaken by my local church. Donations were flooding in, and we needed to keep track of everything, send out receipts, forms and letters of thanks, and note whether each donation was eligible for the UK tax relief known as 'Gift Aid'.
I was keeping track of this using on a PC running the now long-gone Microsoft Works, which, for those less familiar with last-millennium computing, was a software suite incorporating basic and much cheaper versions of the things you found in Microsoft Office: a word-processor, database, and spreadsheet. If your needs were simple, it worked rather well.
Anyway, at one point I was printing out a list of recent donations on my dot-matrix printer, and I noticed what appeared to be some data corruption. In the midst of the sea of donors' names, there were a couple of dates being printed out. Was this a software bug, or was my database file corrupt? I started investigating, while wondering just how much data I'd entered since my last backup and whether I could recreate it...
In the end, the answer was simple, and I breathed a huge sigh of relief. I tried recreating the entry for one of donors and the same thing happened again, at which point I dug a bit deeper and discovered a 'feature' of the app. The lady's first name was 'June', and, though it displayed just fine on the data-entry screen, behind the scenes, it had been turned into 1/6/93! I skimmed quickly through the congregation to find the other problematic record, and found it was for a donation from a lady named 'May'!
When I came back to doing some scientific computing in academia a few years ago, I was surprised and slightly worried to see several of my colleagues processing their data with Excel. It's a wonderful program and very appealing, because of the ease of viewing, checking and plotting graphs of your results, but it comes with lots of problems of its own and shouldn't be used as a substitute for a proper database (if you're a church accountant), or for something like Jupyter Notebooks, if you're a scientific researcher, unless you're exceedingly careful. Last year, more than a quarter of a century after my issues with May and June, 27 human genes were actually renamed because of the number of errors caused in scientific papers by the use of Excel by researchers. The genes' previous names were things like 'SEPT1'.
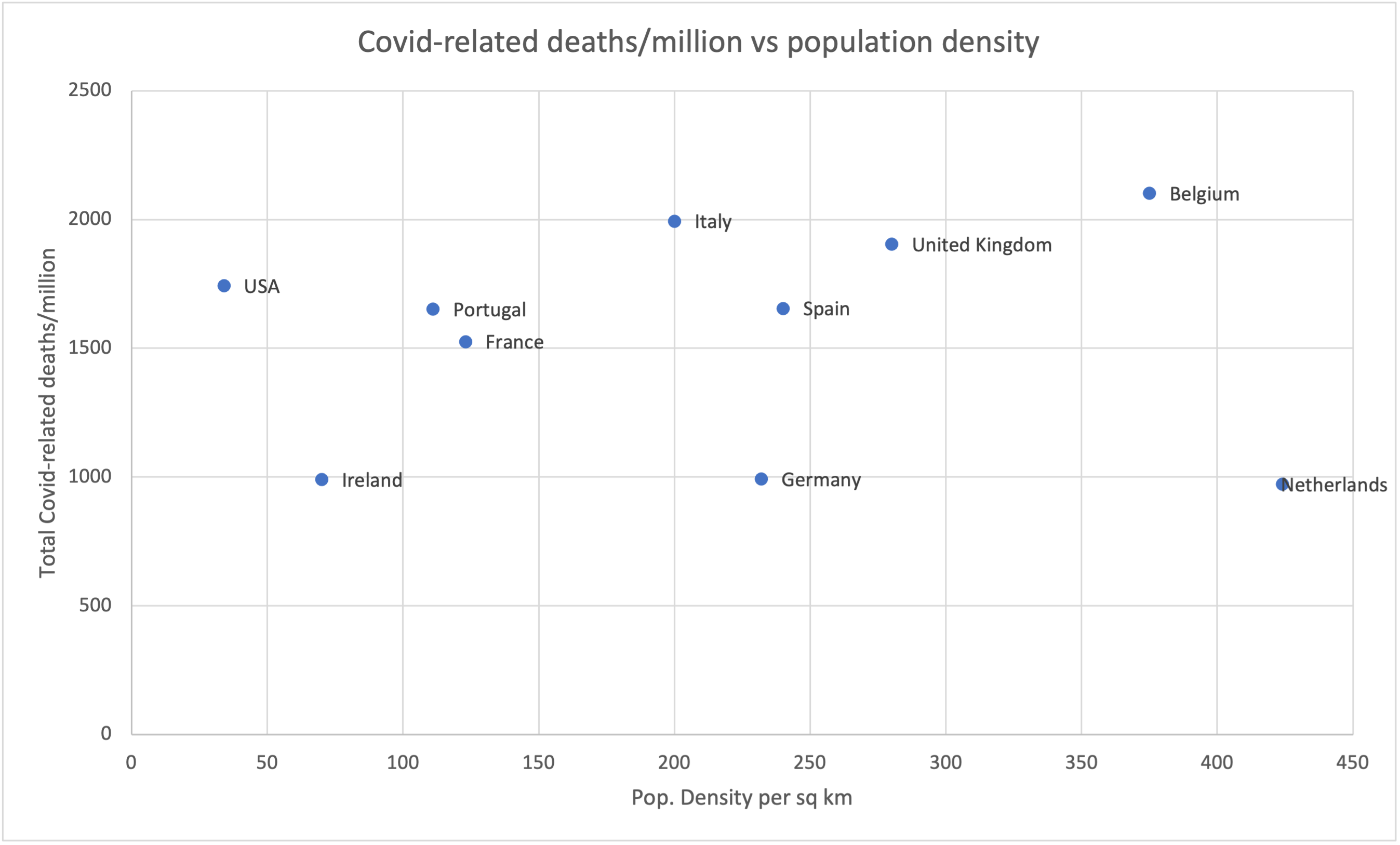
All of this came to mind when reading Tim Harford's enjoyable piece in yesterday's FT, The Tyranny of Spreadsheets. Harford follows the origins of spreadsheets, double-entry bookkeeping and other ways of keeping track of things, up to the famous case last year where 16,000 people weren't promptly told they had positive Covid test results, because somebody had used Excel's old XLS file format, which can only store about 64,000 rows of information, instead of the newer XLSX. That's not really a problem; the problem is that Excel doesn't give you adequate warning when it's discarding data, or changing it in an attempt to be helpful. And the results can be serious.
To quote the article:
Two economists, Thiemo Fetzer and Thomas Graeber ... decided that no catastrophe should be allowed to occur without trying to learn some lessons. They combed through the evidence from Public Health England's mishap. And by comparing the experiences of different regions, they concluded that the error had led to 125,000 additional infections.
...
Fetzer and Graeber have calculated a conservative estimate of the number of people who died, unknown victims of the spreadsheet error. They think the death toll is at least 1,500 people.
Think about that, as you click 'Save As...' and pick your data format.
(Thanks to my sister-in-law Lindsey for the link to the Harford article, which also traces some of the origins of spreadsheets from the 14th century; that's before even I was using them!)