
On Saturday, we had some of the strongest winds I can remember in the UK, at least when I wasn’t on top of a mountain or at sea…
On Saturday, we had some of the strongest winds I can remember in the UK, at least when I wasn’t on top of a mountain or at sea…

And he walked the length of his days under Anglian skies…
 One of the very valuable things to come out of large data centres is large-scale reliability statistics. I’ve written before about my suspicions that my Seagate drives weren’t as reliable as they might be, but I had insufficient data for this to be anything other than anecdotal.
One of the very valuable things to come out of large data centres is large-scale reliability statistics. I’ve written before about my suspicions that my Seagate drives weren’t as reliable as they might be, but I had insufficient data for this to be anything other than anecdotal.
And then a couple of weeks ago, I pulled a couple of old 2.5″ drives off a shelf — Western Digital ones, I think — intending to reuse them for backups. They both span up, but neither would work beyond that.
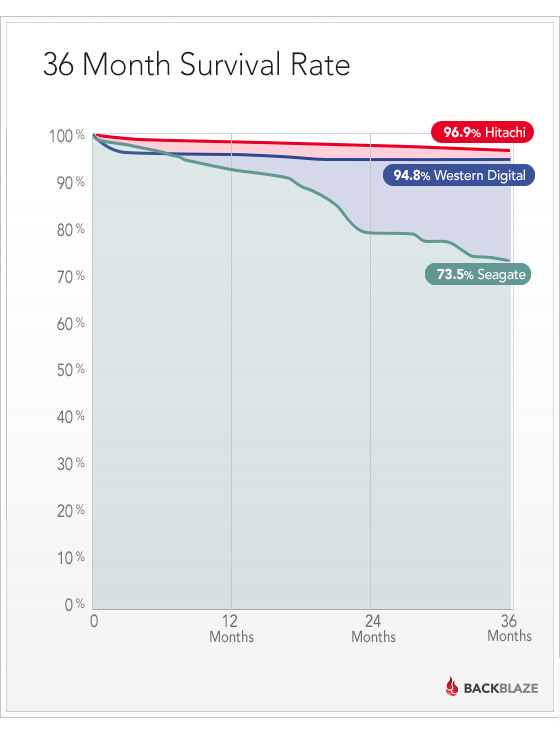
So I was very interested by this Backblaze blog post which discusses their experience with a few thousand more drives than I have at my disposal. They use consumer-grade drives, and are very price-sensitive.
A quick summary:
Some quotes:
Hitachi does really well. There is an initial die-off of Western Digital drives, and then they are nice and stable. The Seagate drives start strong, but die off at a consistently higher rate, with a burst of deaths near the 20-month mark.
Having said that, you’ll notice that even after 3 years, by far most of the drives are still operating.
Yes, but notice, too, that if you have four computers with Seagate drives, you should not expect the data on one of them to be there in three years’ time. And, quite possibly, not there by the Christmas after next.
The drives that just don’t work in our environment are Western Digital Green 3TB drives and Seagate LP (low power) 2TB drives. Both of these drives start accumulating errors as soon as they are put into production. We think this is related to vibration.
and
The good pricing on Seagate drives along with the consistent, but not great, performance is why we have a lot of them.
If the price were right, we would be buying nothing but Hitachi drives. They have been rock solid, and have had a remarkably low failure rate.
and
We are focusing on 4TB drives for new pods. For these, our current favorite is the Seagate Desktop HDD.15 (ST4000DM000). We’ll have to keep an eye on them, though.
Excellent stuff, and worth reading in more detail, especially if longevity is important to you. It’s tempting to fill old drives with data and put them on the shelf as archival backups, but this would suggest that you should only use new drives for that!
Oh, and if you’re wondering about which SSDs to buy, this report suggests that Intel ones are pretty good.
Update: Thanks to Dominic Plunkett for the Backblaze link, and for Rip Sohan for a link in the comments to the TweakTown article that attempts (with some, but not a great deal, of success) to debunk some of this. The previous article I mentioned above links to an older Google study which didn’t distinguish between manufacturers and models, but did say that there was a correlation between them and the failure rates. It also catalogued failure rates not too dissimilar to the Backblaze ones after 3 or so years, so the general implication for home archiving remains!

A geeky post for video editors…
While working on my FCPXchange utility, I did some experiments to see how well Final Cut Pro kept track of files if you moved them around under its feet. I was quite impressed with the results:
Now, exploring a bit further, later, I realised that it can’t be using Spotlight, at least not exclusively, to track the file, because it could still find it even when I put it in a folder explicitly excluded from Spotlight indexing.
And then I realised that all my changes had been moves not copies. If I did anything which involved copying the media and then deleting the original, FCP could no longer track it, whereas, if it were using Spotlight metadata, presumably it could track that in the copy too.
Now, I don’t know much about the deeper workings of HFS+, but I’m guessing that it’s effectively tracking ‘inodes’ here, which means that the same bit of content can be found, whatever name it may have in folders. This, however, will only work with the original copy on the same disk. If you start shifting files around between disks or servers, you’ll thwart it!
…and so I turn to one of the most useful sites for British dog-walkers (cyclists, etc), which can help you answer the questions, “Is it about to rain?” and “How long will this rain last?” At the moment, the former question is largely rhetorical, but the answer to the latter can be very useful.
It was Richard who first pointed me at raintoday.co.uk, which gives you a rough animation of the radar precipitation map over the last couple of hours, so you can get a feeling for how fast the clouds are moving.
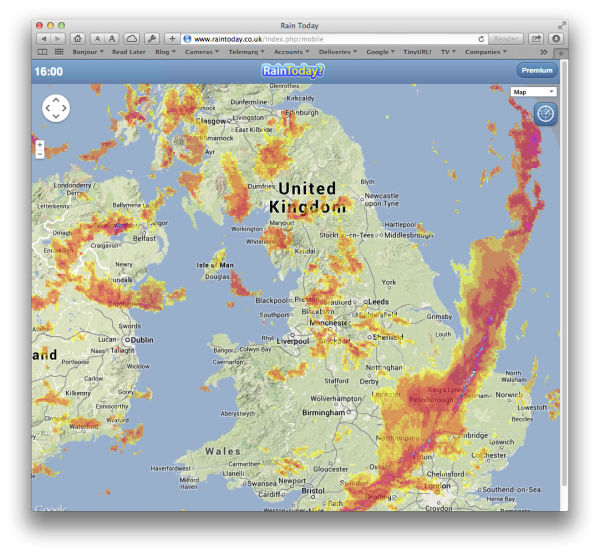
Very very handy. And very British.
It’s also worth knowing that if you put ‘/mobile’ on the end of the URL, you lose some features, but you also don’t get any ads. I have it bookmarked on one of the home screens of my iPhone.
Sorry, people, but I had to write something, having read no less than three posts today by writers who didn’t know the difference between ‘uninterested’ and ‘disinterested’. You can see how that would rankle.
The majority of the time, you probably want ‘uninterested’. That means not paying attention to something because you don’t find it stimulating enough. ‘Disinterested’, on the other hand, means ‘impartial’: having, say, no financial interest in the outcome of a deal. (For anyone even more pedantic than me, I realise that this distinction only became clear in the early 18th century. But I think that should have given most bloggers enough time to catch on by now.)
Anyway, it’s very easy: all you need to do is to remember the phrase my English teacher told me, many moons ago… Are you ready?
“A good judge is disinterested.”
There. Isn’t that easy? Thank you for your attention, everyone. Now I can go to bed with a weight off my mind.
Euan Semple and I have been having similar thoughts. In a perceptive post he writes:
…As people have moved into places like Facebook and Twitter the energy has moved away from blogging to some extent. Less comments and less people using RSS to track conversations. I, like many bloggers, used to post links to my blog posts on Facebook or Google+. Then I realised that I was expecting people to move from where they were to where I wanted them to be – always a bad idea.
So I started posting the entire content of my blog posts on Facebook and Google+. The process is the same, I get the same benefit of noticing things that blogging gives me, the same trails left of what caught my eye, but the conversations have kicked off. I love the forty or fifty comment long threads that we are having. I love the energy of the conversations. It’s like the old days…
And I have to agree. Much as I dislike the tabloid-style, ad-infested nature of Facebook, it does seem to be where the conversations are happening. Yes, some of the smarter people are on Google Plus and App.net, but just not very many of them, and I’m letting my App.net subscription lapse this year. I am even starting to tire a little of Twitter’s 140-character limit and, more so, of the difficulty of having real multi-person conversational threads there. And even though it’s now easy to reply to posts here on Status-Q using your Facebook ID, where your thoughts will be preserved for viewing by other readers, many more people prefer to comment on Facebook or Twitter when I post notifications there.
Euan and I have both been blogging for about 13 years. In that time, a variety of other platforms have come and gone. I expect that quality blogs like his and John’s will outlive Facebook, too. At the very least, I expect that I’ll be able to find good past content on them (see my recent post), long after the social network of the day has changed its ownership, its URL structure, its login requirements or its search engine. So I’m not going to be abandoning Status-Q any time soon: it’s not worth putting much effort into anything that you post only on one of these other platforms.
But his idea of cross-posting the whole text of one’s articles is an interesting one. Facebook is clear, at least at present, that you still own it, though they have a non-exclusive right to make extensive use of it – something those of us who occasionally post photos and videos need to consider carefully.
But I also need to consider the fact that I actually saw his post on Google+, even if I then went to his blog to get a nicely-formatted version to which I could link reliably. Mmm.
Thanks to Tom Standage for pointing me at this fabulous collection of fake signs people have put up on the London Underground.
Some examples:


 or “How to manage too much stuff”
or “How to manage too much stuff”
The now ubiquitous blog format — a timestamped series of posts in reverse chronological order — is a truly wonderful invention.
It’s wonderful for users, who can quickly see whether there’s anything new and get the most up-to-date stuff first. But it’s also wonderful for authors, because it’s immediately obvious to visitors when the content they’re looking at may be out of date. This means authors can almost completely dispense with one of the most tedious management tasks normally associated with any large corpus of information: revisiting what you’ve written in the past and making sure that it’s still correct.
If you’ve ever had to maintain a large website which doesn’t have this kind of built-in auto-obsolescence, you’ll know what I mean. Marketing people, for example, often feel that the more content they can put on the website about their product, the more impressive and compelling it will be. Keeping it updated as the product line evolves, however, then becomes a bit like painting the Forth bridge. The value of blogs, in contrast, is that you don’t need to tidy up after you. So pervasive has the timestamped article become, that I get frustrated when I’m reading a review or an opinion piece which doesn’t show the date. What information was available to the author at the time? Is he reviewing this version of the software or the previous one? Did he know about the competing device from another company?
So, with blogs, we’ve come up with this cunning way of handling the problem of producing too much content. But what about the similar challenge of having too much to consume?
Well, we’re still evolving ways of dealing with that, and we’ve already passed through several stages. I can, because I’m Really Old, remember the time when there were fewer than a dozen websites in the whole world. So it was pretty easy to remember which ones you liked, and when you’d run out of interesting things to read on those, you might start one of your own.
Since then, we’ve moved through a series of different ways of coping with the ever-increasing amount of information.
Now, we’re almost at a couch-potato level of consumption. You fire up your Twitter, Facebook or Google+ app, and information flows past you. Next time you look at it, new stuff will be there. The process of finding new stuff to read has thus been reduced, for most of us, to a single button-click on a phone. Actually typing something into a search engine now constitutes ‘research’, especially if you have to click through more than one or two pages.
This is, arguably, a new kind of page-ranking, where novelty plays a greater role than it ever has before. Yes, some old material gets recirculated, but generally, the river keeps flowing, and this morning’s news will be well downstream by the time you dip your toe in during the afternoon.
Now, novelty is exciting, but it is very different from quality. In fact, it is often the opposite. C.S. Lewis once observed, in an essay called On the reading of old books, that, since there were many more books being published than could ever be read, one very good way of filtering out the dross was to stick to those that had stood the test of time. This is an idea that has stuck with me ever since I first cam across the essay as a child, and I have since tried to read one book written before my lifetime for every one written during it. That is still outrageously biased towards the present, I know, but it’s a start.
Now, how does ‘the test of time’ translate into our modern world? I think there’s an argument that this is a very powerful page-ranking metric that has not yet been fully exploited. (Perhaps, ironically, because it is not a new idea!) Surely, there must be value in knowing which pages people are still reading several years after they first hit the web?
At least once a day, when I’m trying to avoid out-of-date documentation or reviews, I’ll make use of Google’s time-filtering option to limit search results those created in, say, the last year. And in fact, you can create more complex filters to restrict output to particular ranges of dates. So you can search for pages more than 5 years old. (I’m ignoring, for the moment, the fact that the real dates of publication can often be hard to establish. If one newspaper is bought by another and its content copied to a new server, for example, the creation dates may not be preserved very well.) Still, you can, in general, limit your searches to ‘old stuff’.
But Google’s Page Rank algorithms make substantial use of the overall number of times a page is linked to when determining its importance, though they are no doubt biased towards the present. But I really want to know the number of times an old page has been linked to recently: I want a page ranking algorithm based on recently-published pages’ references to older pages.
Can I get an RSS feed of blog posts and web pages that people are still referring to now, but were published more than three years ago? It’s challenging, in a world where even the URLs that worked last year may not work today. But I think would would be worth pursuing. How’s that for a project, Google?
This very carefully-constructed artistic piece is entitled:
Going into the middle of the street to photograph the Christmas lights on the promenade and then having to jump out of the way of an approaching car while on a longer-than-expected exposure.

Snappy, eh? (Click for a larger version)
© Copyright Quentin Stafford-Fraser

Recent Comments